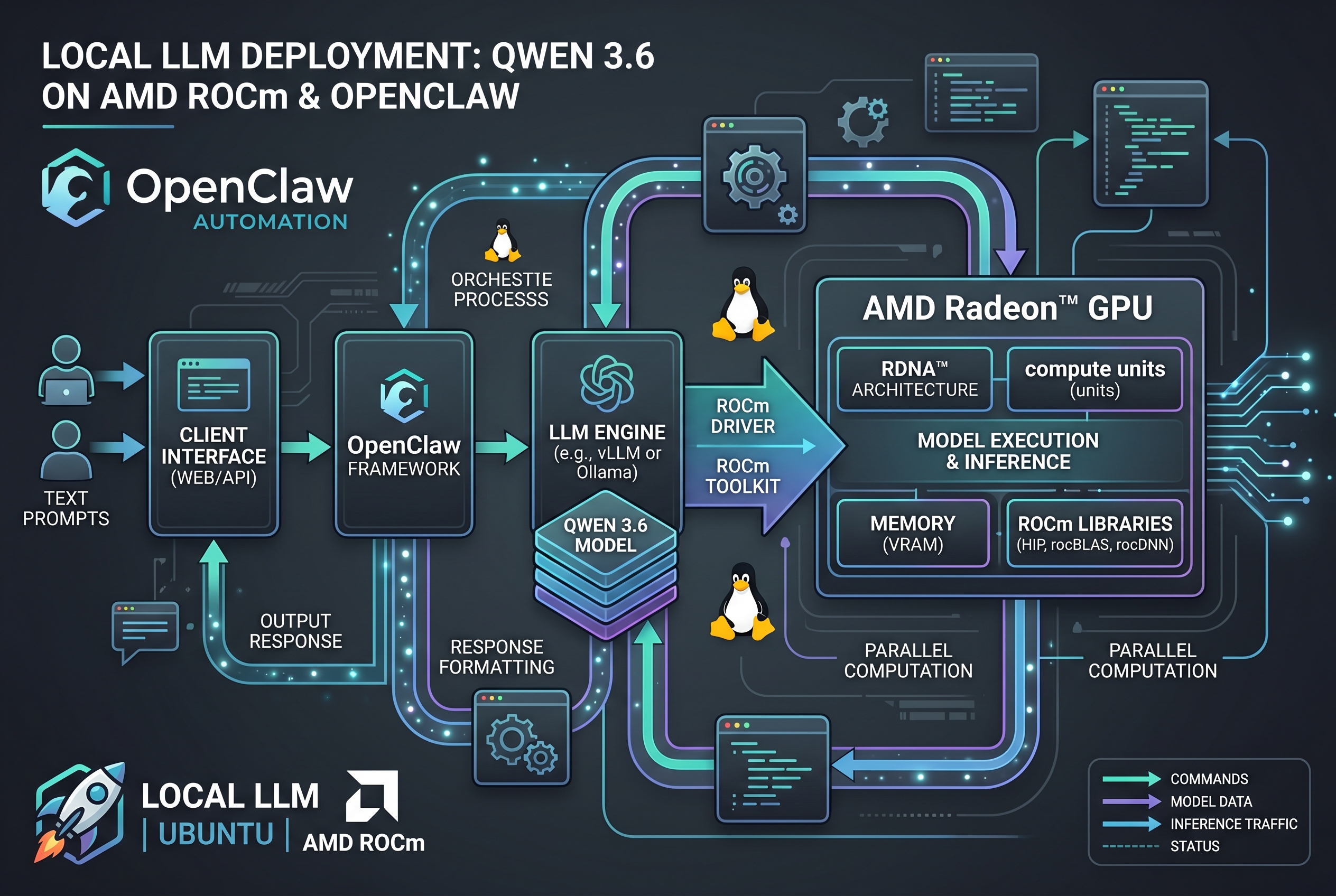
Übersicht
Dieses Issue #30 beschreibt meine langjährigen Erfahrungen mit lokalen LLMs auf Ubuntu — konkret im Einsatz von Qwen 3.6:35B über OpenClaw, Ollama und AMD ROCm. In wenigen Tagen habe ich bereits über 300 Millionen Tokens ausgeführt. Die Infrastruktur läuft stabil, aber einige Optimierungen waren nötig.
Das Modell: Qwen 3.6:35B im Detail
Qwen 3.6-35B-A3B ist ein Mixture-of-Experts (MoE)-Modell mit 35 Milliarden Gesamtparametern, aber nur 3 Milliarden aktiven Parametern pro Token. Das bedeutet: Man zahlt den Speicherpreis für 35B, aber den Rechenpreis für nur 3B. Genau das macht es auf moderater Hardware lauffähig.
Architektur im Überblick
Qwen 3.6 verwendet einen hybriden Attention-Stack mit drei Gated DeltaNet-Schichten für jede Gated-Attention-Schicht. Die DeltaNet-Schichten nutzen lineare Attention — deshalb skalieren diese Modelle nicht in eine Geschwindigkeits-Kluft bei 64K+ Kontextfenstern.
| Eigenschaft | Wert |
|---|---|
| Gesamtparameter | 35B (MoE, 256 Experten) |
| Aktive Parameter / Token | 3B |
| Kontextfenster | 262.144 Tokens |
| Open-Weight Lizenz | Apache 2.0 |
| Quant (Q4_K_M) | ~22 GB VRAM |
| Sprachmodus | Multimodal (Vision eingebaut) |
OpenClaw-Konfiguration im Einsatz
In OpenClaw läuft Qwen 3.6:35B mit folgenden Parametern — optimiert für Stabilität und Geschwindigkeit:
Parameter-Entscheidungen
- temperature: 0.7 — Der Sweet-Spot für Qwen 3.6. Tiefer (0.5) macht das Modell zu deterministisch, höher (1.0) führt bei MoE-Modellen zu mehr „Experten-Rauschen“.
- top_p: 0.9 — Ein bisschen restriktiver als der Standard von 0.95. Bei Qwen 3.6-MoE hilft das, die Experten-Auswahl stabiler zu halten.
- num_ctx: 262144 — Volles Kontextfenster ausgenutzt. Dank der linearen Attention in DeltaNet-Schichten kein Geschwindigkeits-Einbruch wie bei klassischen Modellen.
Benchmark-Referenz: Qwen 3.6-27B dense (der „Flagship“-Vetter) erreicht SWE-bench Verified: 77.2 — auf Augenhöhe mit Claude Sonnet 4.5, nur ~2 Punkte hinter Sonnet 4.6. Und das als open-weight Modell, lokal lauffähig.
Voraussetzungen für stabilen Betrieb
Der reibungslose Betrieb war nicht automatisch gegeben. Zwei kritische Komponenten mussten upgedatet werden:
- ROCm (AMD GPU-Stack) — Die neueste ROCm-Version ist zwingend nötig. Ältere Versionen lieferten fehlerhafte API-Aufrufe, was zu Abstürzen und falschen Token-Ergebnissen führte.
- Ollama (aktuellste Version) — Ollama 0.10+ bringt entscheidende ROCm-Optimierungen mit. Ohne die neueste Version gab es nur instabile Verbindungen zwischen OpenClaw und Ollama.
ROCm-Optimierung auf AMD-GPUs
Für AMD-Nutzer ist der ROCm-Stack entscheidend. Ollama unterstützt AMD GPUs über die ROCm-Bibliothek mit folgenden Anforderungen:
- ROCm v7+ Driver — Installiert über
amdgpu-installvon AMDs ROCm-Dokumentation - BIOS-Einstellungen — iGPU Memory Configuration auf einen höheren Wert (z.B. 96 GB) stellen für bessere Model-Loading-Effizienz
- HSA_OVERRIDE_GFX_VERSION — Falls die eigene GPU nicht offiziell unterstützt wird, kann diese Environment-Variable genutzt werden, um ähnliche LLVM-Targets zu erzwingen
Für NVIDIA-Nutzer gilt entsprechend: OLLAMA_FLASH_ATTENTION=1 aktivieren für 20–30% schnellere Context-Handhabung, und NVIDIA-Treiber mindestens Version 531+. Die Kombination aus Flash Attention und korrektem Treiber macht den Unterschied zwischen „nutzbar“ und „schnell“.
Erfahrungen im Alltagseinsatz
- Geschwindigkeit: Qwen 3.6-35B-A3B läuft auf AMD-GPUs mit ROCm flüssig. Community-Benchmarks zeigen ~101 tok/s auf einer RTX 3090 — auf AMD ähnlich performant bei gleicher VRAM-Kapazität.
- Stabilität: Nach dem Update auf neuestes ROCm + Ollama läuft die Infrastruktur stabil über Tage und Wochen. Vorher: fehlerhafte API-Aufrufe, unerklärliche Abstürze.
- Kontextfenster: 262K Tokens reichen für lange Sessions. Bei >50% Füllwechsel ich aber zu einer neuen Session — das ist der Punkt, wo die Geschwindigkeit merkbar einbricht.
Ab 50% Context-Füllstand wird es langsam. Neue Session erstellen — das sollte für Skill-Creation und andere lange Workflows reichen.
Wichtige Lessons Learned
- Sicherungen vor Änderungen: Vor jeder Änderung an
openclaw.jsoneine Sicherung machen — mitopenclaw backup createund zusätzlich einem GitHub Backup. Das hat mich schon gerettet. - ROCm up-to-date halten: Der AMD-GPU-Stack ist sensibel. Alte Versionen = API-Fehler. Immer die neueste Version von AMDs ROCm-Dokumentation installieren.
- Ollama aktuell: Ollama 0.10+ bringt entscheidende Performance-Boosts für GPU-Beschleunigung. Ältere Versionen sind nicht empfehlenswert.
- Modell-Vergleiche dokumentieren: Ich habe viele Modelle getestet und die Ergebnisse in einer
skill.md-Datei als Zusammenfassung festgehalten — hilft bei zukünftigen Entscheidungen.
Fazit & Empfehlung
Qwen 3.6:35B ist ein ausgezeichnetes Modell für den lokalen Einsatz auf Ubuntu mit AMD-GPU. Die MoE-Architektur macht es auf moderater Hardware lauffähig, wo dense Modelle scheitern würden. Mit der richtigen ROCm- und Ollama-Version läuft es stabil — auch bei mehreren hundert Millionen Tokens.
Empfehlung für den Einstieg:
- Aktuelles ROCm (v7+) + neueste Ollama-Version installieren
- Qwen 3.6-35B-A3B mit UD-Q4_K_M (22 GB VRAM) oder UD-Q3_K_M (16.6 GB)
- OpenClaw mit
num_ctx: 262144,temperature: 0.7,top_p: 0.9konfigurieren - Bei >50% Context-Füllstand neue Session erstellen
- Sicherungen vor jeder Config-Änderung machen!
Für NVIDIA-Nutzer: Der Weg ist ähnlich, nur mit CUDA statt ROCm. Flash Attention aktivieren und Treiber auf dem neuesten Stand halten — das macht den Unterschied.
Schreibe einen Kommentar